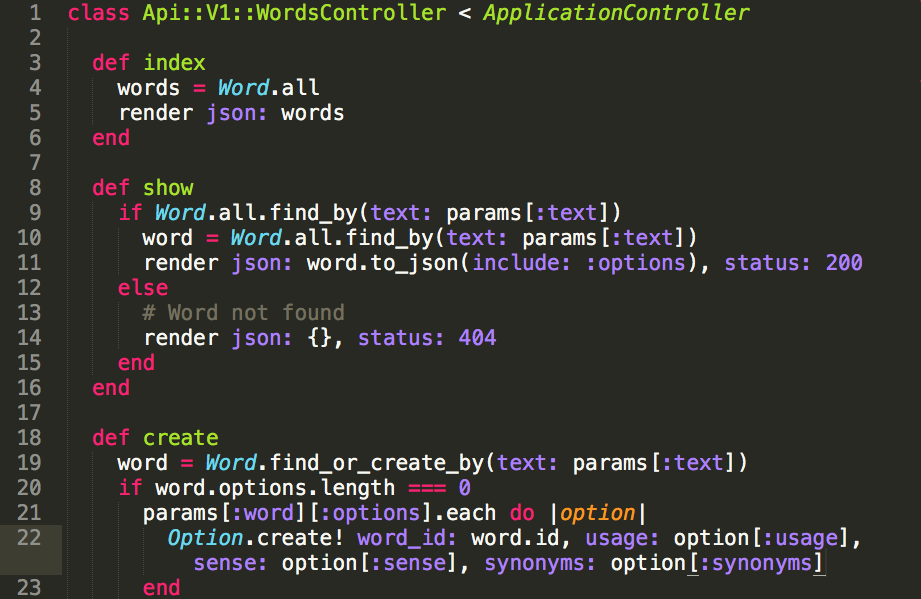
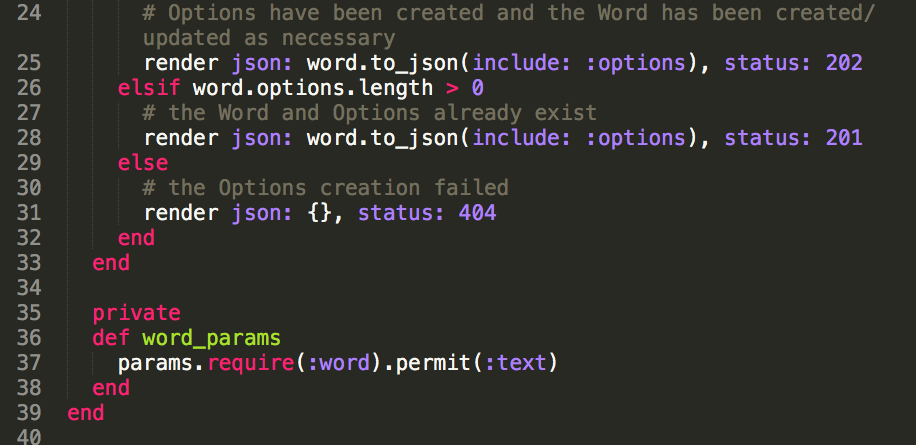
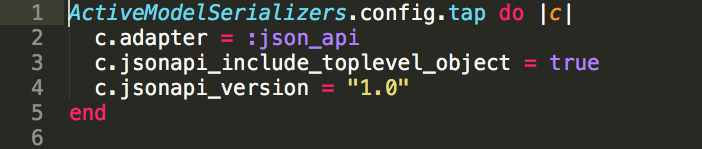
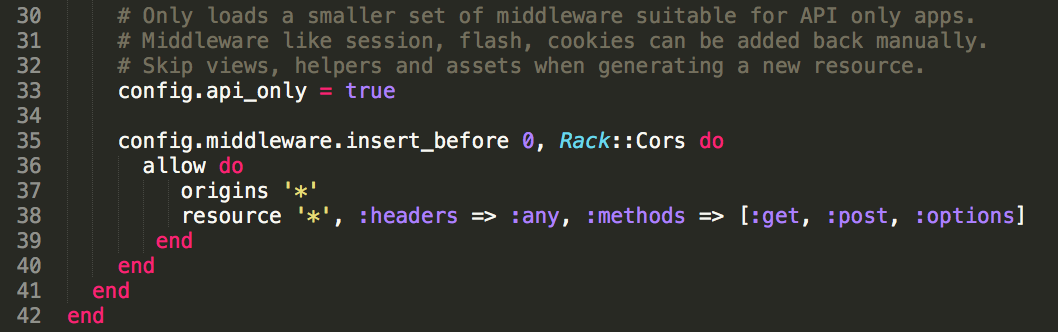
tl;dr
It took some time and distance from my career switch — I personally transitioned from the education world to the technosphere — to have a clearer perspective on the process. I’ve come to the perhaps unsurprising realization that the main similarities between coding and teaching are the hard skills and not the soft, and I’m convinced that this applies to all career changers or potential career changers.
There are different definitions extant for what constitutes a hard and soft skill; this quora post represents the two main viewpoints fairly well. For myself, rather than define hard skills as those which are immutable to a given industry, I’d prefer to define them as those which are immutable to you. After all, why should you have to do all the changing? Admittedly, there is already an existing industry out there, with more domain-specific vocabulary than you can ever hope to internalize, let alone parrot back to your coworkers in an attempt to sound informed. Yet at the same time, you bring your own domain-specific vocabulary with you wherever you go, and you can temper your own feelings of being an imposter by identifying and leveraging them.
For example, if you’ve worked as a barista, I can guarantee that you don’t just know how to serve coffee, and that you don’t merely know how to wear many hats in a demanding sales environment. Those skills may appear to vanish the minute you change your industry, but your experiences and abilities remain with you – they form the core of your transferrable hard skills, and help define your arc as a professional.
For myself, I am not content to leave behind my domain-specific knowledge and acquire new domains. I have a core of hard skills that I bring with me wherever I go, communication and facilitation, which stem from more personal qualities: patience, an open mind, and an ability to consider a problem from any angle. Rather than watering my previous skills down into their softer counterparts and then building them back up (as the received narrative often suggests), my commitment to change industries has only hardened my existing professional skills.